分布式 raft 算法总结
Raft 是一个分布式共识算法,相较于之前普遍使用的 Paxos 算法,Raft 更侧重于算法的简洁和易于理解,并具备支持工业级应用所需的性能。
Raft 有几个区别于其他算法的特性:
- Strong Leader:日志只能从 Leader 发送给 Follower,并覆盖掉 Follower 处与 Leader 不一致的日志。
- Leader Election:Raft 使用随机的延时进行 Leader 的选举,这避免了一些冲突,并使得算法变得更简单。
- Membership changes:Raft 使用 joint consensus 进行在前后两组节点之间进行无缝转变,节点变化的过程对用户而言是透明的。
状态机模型
Raft 的状态机模型如下所示:
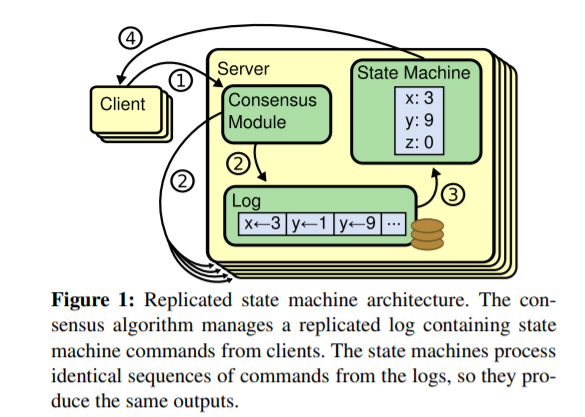
简单的说,一个 Client 的请求过程分为如下四步:
- Client 向 Server Leader 发送一个请求
- Leader 按共识协议将此请求作为一个 Log 存储在一个序列中,并开始在多个节点中进行复制
- 如果对此请求达成共识,便将其应用到状态机中
- 从状态机中返回相应的结果给 Client
Client 的请求可能并不会被按时处理 (Leader 离线、网络延时、一直未达成共识等),对 Client 而言,一个比较合理的操作是超时重试。
但是,Raft 协议本身并不负责处理由于 Client 超时重试而带来的重复日志,这一部分逻辑需要交由上层实体来控制。
Raft 算法综述
Raft 算法需要实现的,就是上述步骤中的第 2 步,也即,Raft 算法需要对传入的 Log 日志在不同的节点间尝试达成共识,如果能达成共识,则将此 Log 应用到状态机中,如果无法达成共识,则废弃此 Log。
Raft 算法主要可以分为如下几个部分:
- Leader election:也即实现中所使用的 Request vote,主要用于发送选举请求,处理选举结果。这一步往往出现在节点刚初始化时或者长时间未接收到来自于 Leader 的消息。
- Log replication:也即实现中所使用的 Append entries,主要用于 Leader 向 Follower 发送日志项,维护 Follower 的心跳时间以免超时重新进行选举等。
- Log compaction:也即实现中所使用的 Install snapshot,主要用于压缩日志项,从而减少开销,如果 Follower 的日志落后太多,为了减少网络开销以及快速进行同步,Leader 会向 Follower 直接发送状态机的快照副本,未在快照中的数据项再通过 Log replication 进行同步。
基本概念
- 任期
term:
数据状态
对于一个 Raft 节点而言,需要维护自身的一些状态,这些状态在论文的 Figure 2 中,主要分了三类:

- 在所有节点上都需要使用的可持久化状态,此类状态每次在更改之后就需要保存到持久化存储中,并在节点重启后载入对应的状态:
currentTerm:节点当前的term,初始时为 0,只增不减,每次收到 RPC 请求时,如果 RPC 中的term比currentTerm大,便更新currentTerm = termvoteFor:节点在 Leader 选举中所投的 Candidate ID,如果未投票则为nulllog[]:节点的日志序列,每个日志都包含一个command,以及command对应的term
- 在所有节点上都需要使用的临时状态,此类状态不必持久化,在每次节点重启后重新初始化即可:
commitIndex:已知的日志序列中可提交的日志 Index 的最大值。初始值为 0, 只增不减lastApplied:已应用到状态机的日志 Index。初始值为 0,随commitIndex递增
- 只在 Leader 节点上使用的临时状态,此类状态不必持久化,并只有选举成为 Leader 后进行初始化即可:
nextIndex[]:对于每个节点,存储需要向其发送的日志项的下一个日志的 Index。初始时为 Leader 的最大的 Log Index + 1matchIndex[]:对于每个节点,保存已知的复制成功的 Log Index 的最大值。初始时为 0,随着日志复制过程递增
- (Figure 13 增加了快照功能之后)增加两个在所有节点上都需要使用的可持久化状态,状态同第一类一样需要持久化保存和载入:
lastIncludedIndex:节点所保存的快照中最后一个日志项的 Index,同时说明 所有index <= lastIncludedIndex的日志项已经被废弃lastIncludedTerm:节点所保存的快照中最后一个日志项的 Term
Leader Election
Raft 使用 Strong Leader 作为共识协议的发起点,因此需要进行选举过程。选举过程的发起需要条件,也就是如果一个 Follower 在设定的时间间隔内一直无法收到 Leader 的消息(心跳),则可以认为之前的 Leader 已经下线或者出现故障, Follower 便会将自身的 currentTerm += 1 ,并转变为 Candidate,向所有的节点发送 RequestVote 的 RPC 请求。
RPC 请求中所包含的参数为:
term:Candidate 的currentTermcandidateId:Candidate 的身份lastLogIndex: Candidate 最后一条日志的 IndexlastLogTerm:Candidate 最后一条日志的 term
同样的,作为此 RPC的接收方,需要对其进行处理并回复,处理的结果如下:
term:最新的term,也即为 Candidate 发送的 RPC 中的term与节点自身currentTerm中的最大值。voteGranted:是否给此 RPC 请求投票,投票时为true
具体的处理逻辑如下:
- 如果 RPC 中的
term大于节点的currentTerm,可知当前的currentTerm任期已经结束,因此节点首先更新自身的currentTerm = term,将身份改为Follower,并清除voteFor - 如果 RPC 中的
term小于节点的currentTerm,不投票,并返回更新的currentTerm - 此时,节点的
currentTerm一定等于 RPC 中的term,是否投票从以下两方面考虑:- RPC中的最新日志信息:只有当RPC中的日志信息比节点的日志信息更新时,才会投票。这个“更新”的意思为:RPC中的
lastLogTerm大于节点最新日志的term,或者RPC中的lastLogTerm等于节点最新日志的term,但RPC中的lastLogIndex大于节点最新日志的index。这一点保证了 Follower 只会给知道的信息比它多的节点投票,从而保证了日志记录的完整性 - 是否在当前任期已经投票:只有在当前任期内此节点未投票或已经给此RPC的id投票时才会确定投票。也即为先到先得。
- RPC中的最新日志信息:只有当RPC中的日志信息比节点的日志信息更新时,才会投票。这个“更新”的意思为:RPC中的
Candidate 需要收集所有的 RPC 回复,并累计所得票数,只有所得的票数超过总数的一半(majority)时,节点才可以成为新一任的 Leader。
安全性保证:对比 commitIndex 的算法逻辑,Leader 只有在超过一半的节点都确认了一个Log的时候,才会将其提交,也就是说:所有提交的日志一定会出现的超过一半以上的节点中。而在选举过程中,如果一个节点不包含这条已经提交的日志,那么它无论无何都无法获得超过一半的选票,也即无法成为 Leader。这保证了所有提交过的日志不会被覆盖,保证了所有节点中应用到状态机的日志序列的一致性。相反地,未提交的日志都有一定的可能会被丢弃。
Log Replication
Raft 算法需要实现日志在不同节点间的同步,以及保证所有提交的日志都是一致的,不存在乱序和差错。因此,Raft 节点需要定期与其他节点进行交互,这个交互是通过 RPC 请求完成的,也就是下面将要说的 AppendEntries。在实际使用中,Leader 需要定期发送此 RPC,目的有两个,一是将新增的 Log 数据复制到 Follower 中,另一个是为了保证 Leader 的存活,毕竟如果 Follower 长时间收不到 Leader 的消息,就会主动发起选举。

AppendEntries RPC所使用的参数如下:
term:Leader 当前的任期leaderId:Leader 的身份prevLogIndex:在entries[]中所包含日志项的前一个日志的 indexprevLogTerm:在entries[]中所包含日志项的前一个日志的 termentries[]:当前 RPC 中所包含的日志项(可以一次发送多个日志以提高效率)。可以为空,表示没有最新的日志项需要发送,只更新 Follower 的心跳。leaderCommit:Leader 当前所提交的日志的 Index,Follower 收到此数据之后便可更新自身的comitIndex,并向自己的状态机应用相关的日志
RPC 的结果所包含的字段如下:
term:最新的term,也即为 Candidate 发送的 RPC 中的term与节点自身currentTerm中的最大值。success:此次日志复制是否成功,在有冲突时返回false
作为 RPC 请求的接收方,处理的逻辑如下:
- 如果 RPC 中的
term大于节点的currentTerm,可知当前的currentTerm任期已经结束,因此节点首先更新自身的currentTerm = term,将身份改为Follower - 如果 RPC 中的
term小于节点的currentTerm,说明此 RPC 来自旧的 Leader,不复制日志,返回更新的currentTerm - 此时,节点的
currentTerm一定等于 RPC 中的term,节点先更新自身的心跳计时,之后考虑日志复制(如果不包含日志则直接返回成功):- **由 Raft 的日志性质,一条日志可以由 index 和 term 唯一确定。**这是由于在每一个 term 内,最多只会产生一个 Leader,因此在相同任期内,日志总是由 Leader 首先接收并复制到 Follower 中,那么 Leader 中日志序列的顺序便是当前 term 中所有日志的顺序。因此,如果两个日志的 term 不同,那么这两条日志一定不是同一个日志;如果两个日志 term 相同,但 index 不同,同样也不是同一条日志。只有 index 和 term 都相同的日志,才能说明此条日志是从相同的 Leader 处复制得到,也就是同一条日志。
- 由于日志复制顺序总是从前向后,只有前面的日志都复制成功后,才会复制下一条日志,因此如果在某条日志处确认了其 index 和 term 都和 RPC 中的一致,那么只需要考虑此条日志之后的日志进行复制,再次之前的日志可以确定都已经与 Leader 处的一致。
- Leader 在 RPC 中会附上
prevLogIndex和prevLogTerm,作为一个日志的锚点,如果 Follower 处存在相同 index 和 term 的日志,便可以进行之后的日志复制,Follower 便可以将 RPC 中的entries[]批量添加到此锚点日志的后面,并在 RPC 中确认复制成功(success = true)。最后,Follower 根据 Leader 的leaderCommit,更新自己本地的commitIndex,并提交相关的日志项。 - 如果
prevLogIndex和prevLogTerm无法对应到 Follower 的日志,说明尚未找到同步点,返回失败(success = false)
在 Leader 处,当接收到了 Follower 的 RPC 的回复后,在此,我们假设此 Follower 的 ID 为 i:
- 如果 reply 中的 term 更大,则变为 Follower
- 如果
success == true:说明复制成功,Leader 需要维护 Follower 的状态,也就是nextIndex和matchIndex:- 在这里令发送的日志项的最后一个日志的 index 为
upper_log_index - 更新
nextIndex[i]为已经发送的日志中的最大的 index + 1。即nextIndex[i] = upper_log_index + 1。 - 更新
matchIndex[i]为已经发送的日志中的最大的 index,即matchIndex[i] = upper_log_index。 - 根据
matchIndex进行判断,如果存在超过一半的节点的matchIndx[i] > N,则可以更新 Leader 的commitIndex,并应用相关日志到状态机。
- 在这里令发送的日志项的最后一个日志的 index 为
- 如果
success == false:说明复制失败,也就是没有找到同步点:- 递减
nextIndex[i],后退一条日志继续尝试同步 。即nextIndex[i] -= 1。
- 递减
一些讨论:
- 初始时,
nextIndex均初始化为 最大的 Log 的index + 1,因此在第一次发送AppendEntriesRPC 时,prevLogIndex等于nextIndex[i] - 1,也即为最大的 Log index,因此此时entries为空,即不包含日志数据。 - 日志的复制过程是从后向前,逐渐尝试进行同步的。对于不同的节点,每次的 RPC 参数会不一样(根据
nextIndex确定)。 - 如何快速找到日志中不一致的地方?这是 Raft 中所使用的一种优化。如果按照原协议,每次日志复制不成功就仅仅将
nextIndex减一,如果日志项比较多,可能会需要很长时间才能完成同步。在这里介绍一个比较常用的回滚算法,加快同步的速度:- 在
AppendEntriesRPC 的回复中新增两个字段:conflictIndex和conflictTerm,其中,conflictTerm为 Follower 处与 Leader 发送的prevLogIndex所冲突的日志项的term,conflictIndex为 Follower 处日志的term等于conflictTerm的第一条日志的index - Leader 接收到这个回复后,检查自己是否包含
conflictIndex和conflictTerm的此条日志,如果包含此条日志,则可以确定冲突的日志在此之后,因此将nextIndex[i]更新为 Leader 处的conflictTerm的最后一条日志的 index;如果不包含,则冲突的日志在此之前,则将nextIndex[i]更新为 Leader 处的conflictTerm的第一条日志的 index。 - 再次补充:为什么将
nextIndex[i]更新为 Leader 处的conflictTerm的最后一条日志的 index?首先,如果 Leader 包含conflictIndex和conflictTerm的此条日志,同时说明 Follower 也有此条日志,因此日志复制失败的原因一定是因为这个 term 下,Follower 处的日志条目不全,否则冲突的位置不会发生在此 term 内。因此将nextIndex更新到这个 term 的最后一条日志的 index,之后再次尝试进行同步。 - 这样的方式可以保证一次跳过一个任期,而不仅仅是一条日志,因此大大加快了同步的速度。
- 在
Log Compaction
随着 Raft 节点日志的不断增加,过多的日志会影响节点的性能开销,因此对日志数据进行压缩是很有必要的。在实现了 Leader Election 和 Log replicate 之后,节点已经实现了基本的 Raft 算法所需的内容,而日志压缩功能则是更进一步,补充之前的协议中缺失的部分内容。
首先,需要明确的是,为什么可以进行日志压缩?回想一下之前所提到的内容,Raft 协议主要关心的并不是全部日志,由于日志顺序的一致性,Raft 协议只需要关注于最新的日志(或最新一部分的日志),而对于陈旧的日志是不会再使用的。比如说,我们选取一个日志作为锚点,那么只要能将此锚点日志对应起来,便可以保证日志的一致性,因此可以丢弃此锚点日志之前的数据,取而代之保存相应的状态机的快照副本。从而,在进行日志复制时,如果需要复制的日志位于此锚点日志之后,那么继续像之前一样传递日志数据;如果位于锚点日志之前,那么首先向其发送快照副本,再发送快照副本之后的日志数据,同样能保证日志的一致性。
其次,什么时候需要创建快照副本?由于创建快照的目的是为了压缩日志,因此可以设置一些阈值,比如已提交但未压缩的日志文件超过一定的大小,或者简单的通过日志数目来衡量是否应该压缩日志。快照的创建是一个本地命令,也就是说不同的节点处可能会存在不同的快照(但均为相同的日志序列,只不过快照所压缩的日志长度有所不同)。
如何确定快照所包含的日志序列?由日志的一致性,可以通过保存快照中最后一条日志的 index 和 term 实现。因此需要向节点添加两个额外的状态,lastIncludedIndex 和 lastIncludedTerm,并且同样需要持久化。
创建快照后,由于之前的日志被丢弃,因此日志的索引范围也将发生变化。简单地说,创建快照之前,index 为 i 的日志在 log 中的 i - 1 处(index 从 1 开始,而 log 从 0 开始索引),创建快照后,index 为 i 的日志在 log 中的 i - 1 - lastIncludedIndex 处,而对于 index <= lastIncludedIndex 的日志不再存在,只能通过复制完整的快照文件。
在进行日志同步时,如果需要 index <= lastIncludedIndex 的日志,将不再通过 AppendEntries RPC 发送日志数据,取而代之我们使用第三种 RPC 命令 InstallSnapshot ,用于发送快照副本文件。

InstallSnapshot RPC 所需的参数如下:
term:Leader 的当前任期leaderId: Leader 的身份lastIncludedIndex:快照所包含的最后一条日志的 indexlastIncludedTerm:快照所包含的最后一条日志的 termoffset:快照文件可能会比较大,需要分片发送,offset标识当前的偏移位置data[]:此次发送的快照数据done:是否已经发送完毕,如果后面不再有数据,则发送true
RPC 的回复只包含 term 一项,用于表示是否成功收到此 RPC。
对于 RPC 请求的处理过程如下:
- 如果 RPC 中的
term大于节点的currentTerm,可知当前的currentTerm任期已经结束,因此节点首先更新自身的currentTerm = term,将身份改为Follower - 如果 RPC 中的
term小于节点的currentTerm,说明此 RPC 来自旧的 Leader,不复制快照,返回更新的currentTerm - 如果当前没有快照文件,则首先新建一个空文件
- 将此 RPC 中的快照数据
data复制到指定的offset处,并逐渐等待更新的快照数据,直至done为true - 丢弃快照文件中所包含的全部日志
- 如果节点当前的日志中存在与
lastIncludedIndex和lastIncludedTerm相同的日志,则保留此日志之后的日志;如果不存在,则丢弃全部日志 - 通过快照文件重置节点的状态机
一些讨论:
- 快照中能否包含未提交的日志?不能,因为快照是通过状态机创建的,而应用到状态机中的所有日志都必须是已经提交的日志。
- 节点在收到快照后,如何将其应用到状态机?可以设置一个单独的命令,在提交日志时标识当前提交的是日志还是快照,如果是日志,则应用到状态机;如果是快照,则重置状态机
Membership Changes
在实际的使用中,Raft 节点的成员配置可能会发生改变,比如增加或减少节点数等。尽管这个步骤可以使用离线更新来实现,但是在离线过程中,会形成一个无法提供服务的窗口。并且离线手动更新难以保证安全性,因此 Raft 协议提供了可以在线更新成员配置的内容。
为了确保安全性,直接在两个配置中进行转变是不行的,因为这有可能导致在同一个 term 下选举出了两个 Leader。因此我们必须将这个步骤拆分为两个阶段。比如第一步中先停止先前的配置文件并暂停服务,第二步载入更新的配置并恢复。
在 Raft 中,集群首先进入一个临时的配置状态,称之为 joint
consensus;一旦 joint
consensus 被提交到日志,整个系统便过渡到最终的阶段,并可以使用更新的配置。
参考资料
分布式 raft 算法总结

