SQL 必知必会 - 单表查询/过滤/汇总
SQL 必知必会 - 全书目录
- 第 01 - 10 章:SQL 必知必会 - 单表查询/过滤/汇总
- 第 11 - 24 章:SQL 必知必会 - 多表查询/联结/组合
- 第 15 - 24 章:SQL 必知必会 - 数据更新/存储/事务
基础
- SQL(发音为字母 S-Q-L 或 sequel)是 Structured Query Language(结构化查询语言)的缩写
- SQL 是一种专门用来与数据库沟通的语言
- 标准 SQL 由 ANSI 标准委员会管理,从而称为 ANSI SQL
- 数据库(database): 保存有组织的数据的容器(通常是一个文件或一组文件)
- 数据库软件应称为数据库管理系统(DBMS)
- 表(table): 某种特定类型数据的结构化清单
- 模式(schema): 关于数据库和表的布局及特性的信息
- 列(column): 表中的一个字段, 所有表都是由一个或多个列组成的
- 行(row): 表中的一个记录, 有时也称其为数据库记录(record)
- 数据类型: 所允许的数据的类型. 每个表列都有相应的数据类型, 它限制(或允许)该列中存储的数据
- 主键(primary key): 一列(或一组列), 其值能够唯一标识表中每一行
- 表中的任何列都可以作为主键,只要它满足以下条件:
- 任意两行都不具有相同的主键值
- 每一行都必须具有一个主键值(主键列不允许
NULL值) - 主键列中的值不允许修改或更新
- 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)
检索数据 - SELECT
- 每句 SQL 语句都建议使用
;结尾; 所有空格会被忽略 - 行内注释使用
--或#(一般不使用), 多行注释使用/* ... */ - 在不指定排序的情况下, 输出没有特定的顺序
- SQL 语句不区分大小写, 但习惯上对 SQL 的关键词使用大写, 对列名和表名使用小写
- 使用
DISTINCT去重输出不同的值, 作用于所有的列 - 限制输出的结果数目:
- SQL Server, Access: 使用
TOP关键字 - DB2:
FETCH FIRST 5 ROWS ONLY; - Oracle:
WHERE ROWNUM <=5; - MySQL, MariaDB, PostgreSQL, SQLite:
LIMIT子句和OFFSET子句
- SQL Server, Access: 使用
1 | -- 检索单个列 |
排序检索数据 - ORDER BY
- 在指定一条
ORDER BY子句时,应该保证它是SELECT语句中最后一条子句 - 可以使用未检索的列进行排序
- 支持按相对列位置, 此时不能使用未检索的列进行排序
- 默认为
ASC或ASCENDING升序排序, 降序排序使用DESC或DESCENDING DESC关键字只应用到直接位于其前面的列名, 指定多个列时, 每个列都需要DESC关键字
1 | SELECT prod_name |
过滤数据 - WHERE
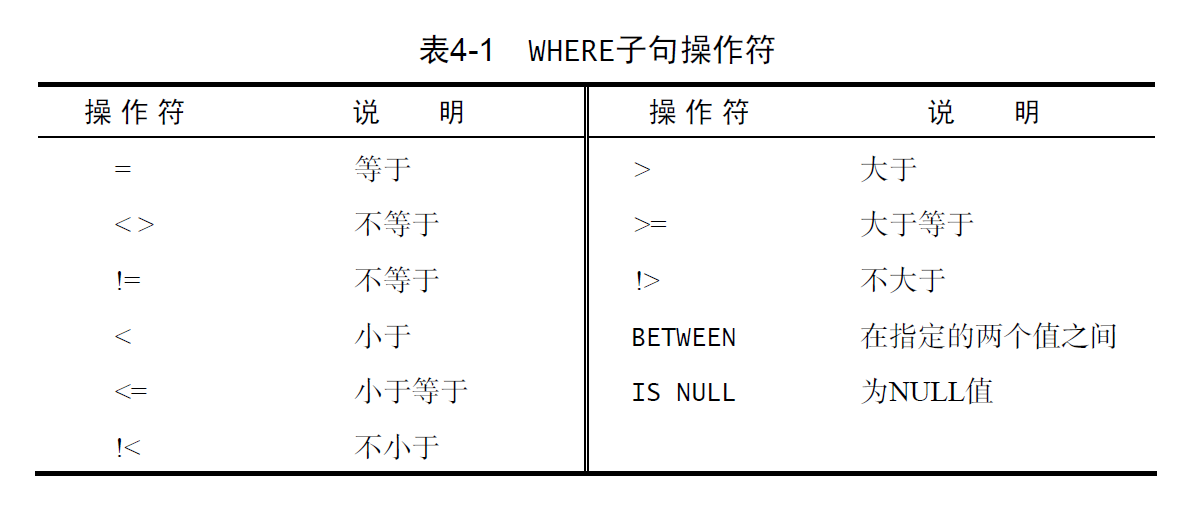
- 使用
SELECT语句的WHERE子句指定搜索条件 WHERE语句支持的操作符如下图, 注意某些操作符是冗余的, 具体支持参阅对应的数据库软件实现BETWEEN操作符需要两个值,即范围的开始值和结束值BETWEEN匹配范围中所有的值,包括指定的开始值和结束值- 空值检查: 特殊的
WHERE子句:IS NULL子句 NULL和非匹配: 在进行匹配过滤或非匹配过滤时, 不会返回值为NULL的行。
1 | -- 一些常用的例子 |
高级数据过滤 - AND/OR/IN/NOT
SQL允许给出多个WHERE子句, 以AND子句或OR子句的方式使用AND操作符用来指示检索匹配所有给定条件的行OR操作符用来指示检索匹配任一条件的行- 支持短路求值,
AND的优先级比OR高, 可使用圆括号()手动指定优先级 IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配- 等同于
OR操作符, 但IN操作符的语法更清楚,更直观。 - 在与其他
AND和OR操作符组合使用IN时,求值顺序更容易管理 IN操作符一般比一组OR操作符执行得更快IN的最大优点是可以包含其他SELECT语句,能够更动态地建立WHERE子句。
- 等同于
NOT操作符否定其后所跟的任何条件, 总是与其他操作符一起使用- 部分场景下也可用
<>操作符来替代 - 在更复杂的子句中,
NOT是非常有用的
- 部分场景下也可用
1 | SELECT prod_id, prod_price, prod_name |
用通配符进行过滤 - LIKE/%_[^]
- 利用通配符,可以创建比较特定数据的搜索模式, 用来匹配值的一部分
- 通配符搜索只能用于文本字段(字符串), 非文本数据类型字段不能使用通配符搜索
- 百分号
%通配符: 表示任何字符出现任意次数- Microsoft Access 中需要使用
* - 是否区分大小写与数据库有关
- 能匹配 0 个字符, 代表搜索模式中给定位置的 0 个、1 个或多个字符
- 许多 DBMS 都用空格来填补字段的内容, 使用
%时需要考虑末尾填充的空格 %不会匹配产品名称为NULL的行
- Microsoft Access 中需要使用
- 下划线
_通配符: 只匹配单个字符- DB2 不支持通配符
_, Microsoft Access中需要使用?
- DB2 不支持通配符
- 方括号
[]通配符: 匹配方括号中任意单个字符- 不是所有 DBMS 都支持用来创建集合的
[] - 可以用 前缀字符
^(脱字号)来否定 - Microsoft Access 中需要用
!来否定
- 不是所有 DBMS 都支持用来创建集合的
- 通配符搜索一般比前面讨论的其他搜索要耗费更长的处理时间
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,也尽量不要把它们用在搜索模式的开始处。把通配符置于开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
1 | -- % |
创建计算字段 - AS/+||
- 拼接字段: 将值联结到一起(将一个值附加到另一个值)构成单个值。
- Access 和 SQL Server 使用
+号 - DB2, Oracle, PostgreSQL, SQLite 和 Open Office Base 使用
|| - MySQL 和 MariaDB 中使用特殊的函数
Concat
- Access 和 SQL Server 使用
- 使用别名: 用
AS关键字- 有时也称为导出列 (derived column)
- 执行算术计算: 支持
+-*/- 圆括号可用来区分优先顺序
- 省略了
FROM子句后就是简单地访问和处理表达式
1 | -- 拼接字段, 使用别名 |
使用函数处理数据 - 函数
- 只有少数几个函数被所有主要的 DBMS 等同地支持
- 与 SQL 语句不一样, SQL 函数不是可移植的
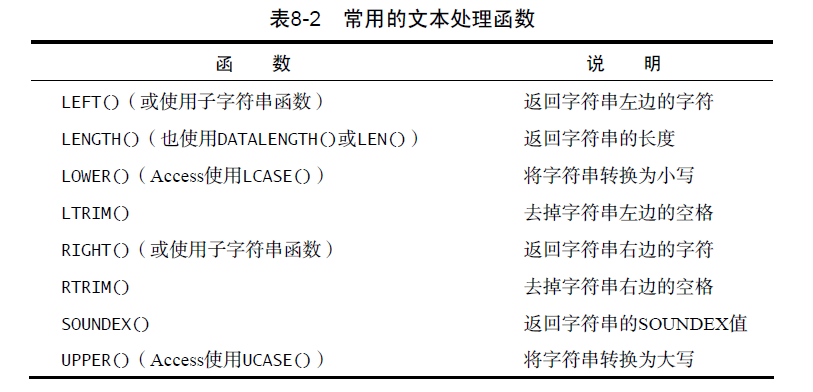
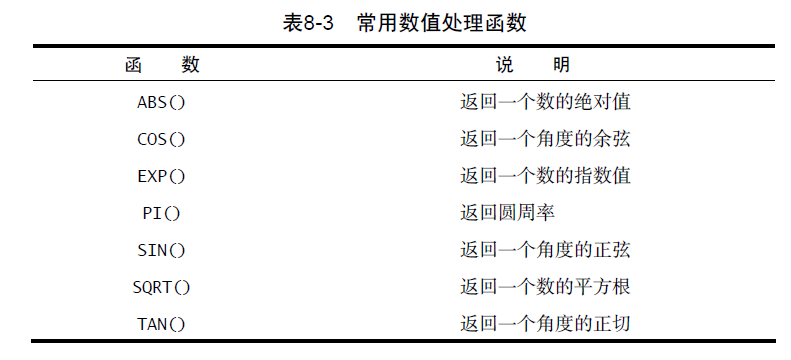
- 大多数 SQL 实现支持以下类型的函数
- 用于处理文本字符串(如删除或填充值,转换值为大写或小写)的文本函数
SOUNDEX()是一个将任何文本串转换为描述其语音表示的字母数字模式的算法
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数
- 用于处理日期和时间值并从这些值中提取特定成分(如返回两个日期之差,检查日期有效性)的日期和时间函数
- 返回 DBMS 正使用的特殊信息(如返回用户登录信息)的系统函数
- 用于处理文本字符串(如删除或填充值,转换值为大写或小写)的文本函数

1 | -- 使用 SOUNDEX() 函数进行搜索, 匹配所有发音类似于 Michael Green 的联系名: |
汇总数据 - 聚集函数
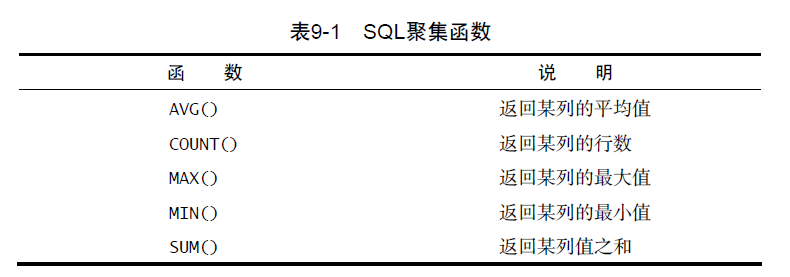
- 聚集函数: 汇总数据而不用把它们实际检索出来
AVG()只能用来确定特定数值列的平均值, 而且列名必须作为函数参数给出- 只用于单个列
- 忽略列值为
NULL的行
COUNT()确定表中行的数目或符合特定条件的行的数目COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
MAX()/MIN()返回指定列中的最大/小值, 要求指定列名, 忽略列值为NULL的行- 允许将它用来返回任意列中的最大/小值
SUM()用来返回指定列值的和(总计), 忽略列值为NULL的行。- 聚集不同值:
- 对所有行执行计算,指定
ALL参数或不指定参数(因为ALL是默认行为)。 - 只包含不同的值,指定
DISTINCT参数。 DISTINCT必须使用列名, 只能用于COUNT(),DISTINCT不能用于COUNT(*)
- 对所有行执行计算,指定
- 组合聚集函数
1 | -- 计算平均值 |
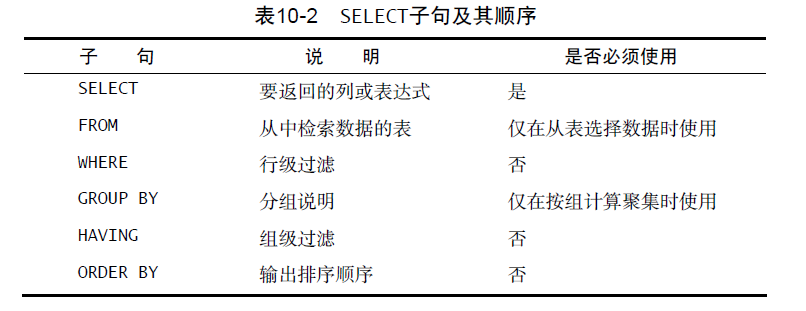
分组数据 - GROUP BY/HAVING
- 使用分组可以将数据分为多个逻辑组, 对每个组进行聚集计算
- 创建分组: 使用
SELECT语句的GROUP BY子句- 可以包含任意数目的列,因而可以对分组进行嵌套
- 如果在
GROUP BY子句中嵌套了分组,数据将在最后指定的分组上进行汇总 - 列出的每一列都必须是检索列或有效的表达式, 不能使用别名
- 大多数 SQL 实现不允许
GROUP BY列带有长度可变的数据类型 - 除聚集计算语句外,
SELECT语句中的每一列都必须在GROUP BY子句中给出 - 如果分组列中包含具有
NULL值的行,则NULL将作为一个分组返回. 如果列中有多行NULL值,它们将分为一组 GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前
- 过滤分组:
HAVING子句WHERE过滤指定的是行,HAVING过滤指定的是分组HAVING支持所有WHERE操作符WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤WHERE排除的行不包括在分组中, 这可能会改变计算值, 从而影响HAVING子句中基于这些值过滤掉的分组- 如果不指定
GROUP BY, 则大多数 DBMS 会同等对待它们
- 分组和排序
- 一般在使用
GROUP BY子句时, 应该也给出ORDER BY子句 - 这是保证数据正确排序的唯一方法, 千万不要仅依赖
GROUP BY排序数据
- 一般在使用

1 | -- GROUP BY 子句指示 DBMS 按 vend_id 排序并分组数据 |
SQL 必知必会 - 全书目录
- 第 01 - 10 章:SQL 必知必会 - 单表查询/过滤/汇总
- 第 11 - 24 章:SQL 必知必会 - 多表查询/联结/组合
- 第 15 - 24 章:SQL 必知必会 - 数据更新/存储/事务
SQL 必知必会 - 单表查询/过滤/汇总

